Deep Learning to Identify Smartphone Applications
Overview
Teaching: 15 min
Exercises: 10 minQuestions
What are the security challenges related to smartphones?
What approaches are being used by security researchers to devise better ways to secure mobile devices?
How can large datasets like SherLock help researchers detect security issues on smartphones?
How can the SherLock dataset be used to develop a method for identifying smartphone apps?
Objectives
Explain the convenience and security risks of the use of mobile devices such as smartphones.
Understand how machine learning (ML) can be leveraged to improve the security of mobile computing.
Understand the approach to identifying smartphone apps using ML methods.
Understand how ML-based smartphone app identification may lead to the detection of malware apps.
Review the reduced SherLock dataset introduced in the Machine Learning lesson module.
Security Challenges for Mobile Device Users
Smart phones and mobile devices have become an essential part of modern daily life. These devices store a large amount of sensitive personal data, such as emails, messages, documents, contact information, pictures and videos. Mobile apps provide convenient access points to additional sensitive information, such as financial accounts, health data, business and legal information, and much more. It is not surprising that malicious hackers consider these mobile devices as attractive targets for stealing sensitive personal information that can be exploited for fraudulent gain.
Hackers have devised different tactics to infiltrate personal mobile devices, but the most prevalent method has been the use of malicious apps (often called malware). Malware is often disguised as a “cool” free app or utility software or is bundled within another app. Once malware is installed on a device, the possibilities for the hacker are endless: spying and stealing personal data are just two examples. For this reason, malware detection and removal is a very important part of mobile cyber defense mechanisms. Because cyberthreats (malware included) continue to evolve rapidly, protecting the security of mobile devices has always been a difficult task. Security researchers continue to develop alternative ways to get one step ahead of malicious hackers. Many researchers have turned to artificial intelligence (AI), more specifically, machine learning (ML), to devise novel and smarter ways to enhance mobile device security.
The SherLock Android Smartphone Dataset
While access to realistic datasets is always paramount in any cybersecurity research, state-of-the-art AI/ML requires large amounts of data to train and validate the models. The SherLock Dataset, furnished by security researchers at the Ben-Gurion University of the Negev (BGU) in Israel, is a very comprehensive dataset on Android smartphones that is available for academic security research. It contains a massive amount of data (totaling over 10 billion records, or 6 terabytes) collected from smartphones used by fifty volunteers over a period of more than two years. The SherLock dataset was developed to help researchers devise better ways to detect malicious activities and other security issues on smartphones.
About the SherLock Dataset
The SherLock dataset is a long-term dataset of smartphone sensors and system probes with a high temporal resolution. The dataset was made to capture activities occurring on Android smartphones, of which the vast majority are benign. An artificial malware named “Moriarty”, created by the researchers, was installed on the phones. Moriarty would occasionally exhibit malware-like activities, which are also recorded in the SherLock dataset. This dataset contains a record of the activities on these smartphones, which are a combination of real, legitimate activities performed by the users, the apps, and running services and the malware-like activities occasionally exhibited by Moriarty.
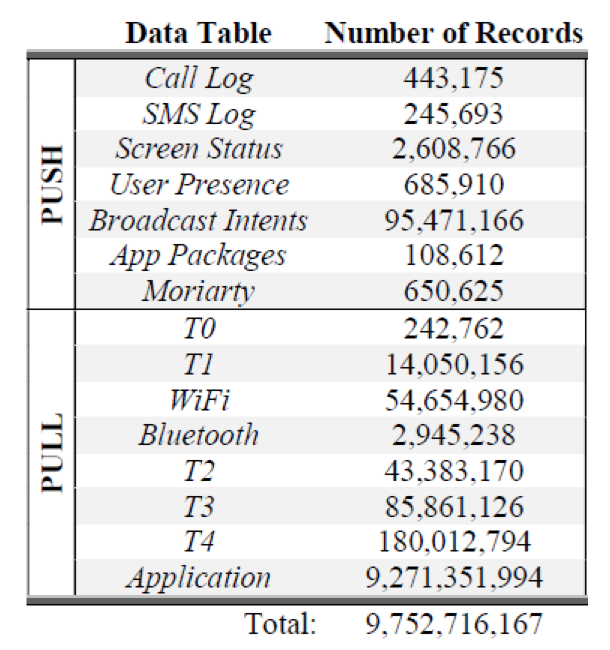
Figure: Data tables and number of records in the full SherLock dataset (as of August 2016) (Source: SherLock team)
The table above summarizes the different kinds of data collected and gives a sense of the magnitude of the data. The
Applicationstable has the largest number of records: It contains resource utilization snapshots per running app (CPU, memory, network, etc.), captured at a high resolution. We focus only on this table in this lesson.We provide a detailed background of the challenges in mobile device security, as well as a description of the SherLock experiment and dataset, in our Big Data lesson, in the episode titled “Big Data Challenge: Detecting Malicious Activities on Smartphones”. We recommend that learners first read that episode if they are not familiar with the SherLock dataset. Interested learners can find more details about the SherLock project and dataset on the authors’ website (archived) and their 2016 AISec paper.
{kind=link}
Machine Learning Objective
Smartphone Application Classification
How can researchers leverage the SherLock dataset to address mobile security challenges? Focusing only on the area of malware detection, SherLock can be used to characterize the behavior of different apps, both legitimate apps and malware. Using ML techniques, we can tease out the differences between normal versus malware activity patterns and detect activities that do not correspond to normal (legitimate) apps. At the core of this detection is the application classification task to be performed by the ML model.
Our machine learning objective is to distinguish the applications that are currently running on a smartphone.
In the previous lesson module on
Machine Learning,
we used the SherLock dataset to build several ML models,
i.e. logistic regression and decision tree,
to classify (distinguish) smartphone apps.
The models were trained on a large set of training data
to learn the characteristics of resource utilization
of the different apps.
Each record in the dataset comes with a label, which is the application name.
The trained model can be used to distinguish the different apps
running on a smartphone.
We used a very limited subset of the sample SherLock Applications table,
reduced to contain only two popular applications: WhatsApp and Facebook.
Using Machine Learning to Detect Malware
The application classification ML method can be further adapted to detect malware that is running on a phone. A proof-of-concept work was elaborated by computer scientists Wassermann and Casas in their 2018 “BIGMOMAL” paper. After successfully building a ML model to classify running apps, they trained a second model to detect the presence of Moriarty “malware” on a phone while the malware was running. The authors showed that in certain limited cases, the approach based on the
Applicationstable does work quite well; however, generalizing this to multiple users and use scenarios has its own challenges.We exclude this malware classification task from this module; interested learners are encouraged to try creating malware-detecting models on their own as a challenge problem. After completing this module, they should be prepared to train and validate “Moriarty detection” ML models.
Comparing Neural Networks to Traditional Machine Learning Methods
In this lesson module,
we will construct and train ML models based on neural networks (NN)
to perform the application classification task.
Initially, the same dataset introduced in the
Machine Learning module will be used
so that we can compare the performance of NN against
the traditional ML models.
We will further challenge all these ML models
to perform the classification task on a richer subset of the Applications table
with more running apps.
Will the decision tree model still far outshine logistic regression?
How much more, if any, can the NN models be improved upon
to outperform the other methods?
The following is the framing question we will consider throughout this lesson module:
Will neural network models perform better than traditional ML modules? If so, by how much?
We will revisit this question several times in the hands-on activities.
Reduced Dataset 1: The Preprocessed sherlock_2apps Table
Required Python Modules
For the hands-on activities in this episode, we only need to load
pandas, as we will only carry out a little bit of data exploration:import pandas as pdStarting from the next episode, many more Python modules, classes and functions will be needed.
We revisit the reduced subset of the Applications table
introduced in the Machine Learning lesson module.
The limited table, called sherlock_2apps,
contains resource utilization data from only two applications:
Facebook and WhatsApp.
Data from this table were used to train several traditional ML models
to classify (distinguish) two running apps.
This special task of distinguishing two classes is called
binary classification.
Technically, the model only needs to output one value:
either 0 or 1 (in this case, 0 stands for Facebook and 1 for WhatsApp).
As we shall see in the next episode, it is straightforward to create
an NN model for a binary classification task.
The sherlock_2apps data underwent
a sequence of preprocessing steps
to make them suitable for training ML models.
Briefly, these steps are as follows:
-
Data cleaning (such as: removal of irrelevant or duplicate features, dealing with missing data);
-
Separating labels from features;
-
Feature scaling;
-
Feature selection.
The last step reduced the number of features in the final dataset
to just four
(cutime, num_threads, otherPrivateDirty, priority).
In this episode, we will start with this preprocessed dataset.
The preprocessed data consists of two tables:
one for the features, and the other for the labels.
Let us load them now:
df2_features = pd.read_csv('sherlock/2apps_4f/sherlock_2apps_features.csv')
df2_labels = pd.read_csv('sherlock/2apps_4f/sherlock_2apps_labels.csv')
Initial Data Examination
Please do an initial examination of the preprocessed dataset:
- Confirm the count and names of the features in this preprocessed dataset.
- What are the values of the labels?
- Confirm that there are no more missing values in the tables.
- Show that the data have been rescaled (hint: check the statistics).
Example Solutions
These are not the only solutions. Other solutions exist, as long as the questions above are answered satisfactorily.
print("Features:") print(df2_features.head(5)) print() print("Labels:") print(df2_labels.head(5))Features: cutime num_threads otherPrivateDirty priority 0 -0.429029 -1.300898 -0.780597 0.246368 1 -0.429029 0.222698 -0.688933 0.246368 2 -0.429029 -0.292636 -0.321111 0.246368 3 -0.429029 -1.300898 -0.785560 0.246368 4 -0.429029 0.222698 -0.687036 0.246368 Labels: ApplicationName 0 0 1 0 2 1 3 0 4 0The commands above show the column names (the features) and representative values of each column. This includes the first 5 values of the labels (0 for Facebook and 1 for WhatsApp).
df2_features.info() print() df2_labels.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 612114 entries, 0 to 612113 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 cutime 612114 non-null float64 1 num_threads 612114 non-null float64 2 otherPrivateDirty 612114 non-null float64 3 priority 612114 non-null float64 dtypes: float64(4) memory usage: 18.7 MB <class 'pandas.core.frame.DataFrame'> RangeIndex: 612114 entries, 0 to 612113 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 ApplicationName 612114 non-null int64 dtypes: int64(1) memory usage: 4.7 MBThe commands above show the data type of each column and that there are no more missing data (the column Count returning non-null).
Now, do some statistical checks:
print(df2_features.describe()) print() print(df2_labels.value_counts())cutime num_threads otherPrivateDirty priority count 6.121140e+05 6.121140e+05 6.121140e+05 6.121140e+05 mean -2.572250e-13 -6.487132e-14 -5.919865e-16 -4.247862e-13 std 1.000001e+00 1.000001e+00 1.000001e+00 1.000001e+00 min -4.290290e-01 -1.502551e+00 -7.912521e-01 -1.151783e+01 25% -4.290290e-01 -4.942885e-01 -7.102436e-01 2.463679e-01 50% -4.290290e-01 -1.582011e-01 -3.384800e-01 2.463679e-01 75% -4.290290e-01 5.363795e-01 3.038959e-01 2.463679e-01 max 5.414514e+00 2.575310e+00 1.103249e+01 2.463679e-01 ApplicationName 0 379054 1 233060 dtype: int64The first print output shows that the mean values are virtually zero and that the standard deviations are one (for each feature). This proves that the data was rescaled. The second print output shows the distribution of values in the labels; there are only two values, i.e. 0 and 1.
Splitting Data into Training and Validation Sets
As the last data preparation step for machine learning,
we need to split the dataset into training and validation sets.
Use scikit learn’s train_test_split method, which allows the user to specify the size of the train or test dataset as a proportion of the given dataset.
Then, the data is ready for ML training:
from sklearn.model_selection import train_test_split
train_F, val_F, train_L, val_L = train_test_split(df2_features, df2_labels, test_size=0.2)
In the upcoming episodes, we will use this dataset to train and validate NN models. The traditional ML models were trained and validated in the Machine Learning lesson, the results of which we will use as a reference to benchmark our NN models.
Key Points
Malicious apps (malware) have become a prevalent tool for compromising mobile devices, stealing personal information, or spying on a user’s activities.
Researchers have leveraged artificial intelligence (AI) / machine learning (ML) to keep up with increasing security challenges.
Large amounts of data are critical to train and validate accurate and effective ML-based cybersecurity techniques.
ML models can be used to distinguish smartphone apps and potentially identify malware.