Big Data Challenge: Detecting Malicious Activities on Smartphones
Overview
Teaching: 10 min
Exercises: 0 minQuestions
What are the security challenges related to smartphones?
What are the goals of big data analytics in cybersecurity?
What is the Sherlock dataset?
What are the potential uses of the Sherlock dataset?
Objectives
Learn the basic aspects of malware.
Introduce the Sherlock Dataset.
Introduce the overarching goal of this lesson module.
Background
Smartphones have become an ubiquitous technology that many people have relied upon. A great fraction of people in the developed parts of the world run their daily activities on these devices, such as exchanging e-mails and text messages, accessing bank and financial accounts, paying bills, performing important transactions such as buying and selling homes, capturing memories, and many more. There is a large amount of personal and sensitive information stored on these devices, making them a prime target for cyber attacks. Hackers have employed various means to gain access and control of these phones—most often with a motivation of gaining illicit financial profits, but at other times with a malicious intent of inflicting harm (like stalking, bullying, and snooping and spying). Malware (malicious software) is a very common vector for cyber attacks: users are lured or pressured to install certain applications which purport to be useful (e.g. games, data/junk cleaners, even sometimes antivirus or ad blockers!). Once installed, the malware will perform illicit activities such as logging your key strokes to steal user names and passwords; stealing your address book, text messages, or email messages; silent recording of audio, pictures, or videos; posting notifications with links to malicious websites.
Of particular interest are malware affecting smartphones running Android operating system (OS). Google’s Android is by far the most popular smart phone operating system. It is relatively easy to install arbitrary applications on Android phones—which makes it easy for crooks to gain access into these phones through malware. (For sure, iPhone malware does exist but the prevalence appears to be lower, partly due to much stricter security constraints on these devices.)
We, the users of computing technology, have an important responsibility to defend ourselves against these kinds of cyberattacks. This begins with the common-sense defensive practices such as: (1) downloading and installing applications only from trusted software store (Google Play Store or Apple Store); (2) never click links on a suspicious email, text message, or website; (3) refrain visiting websites that have questionable contents or credibility; (4) exercising caution and judgment when connecting to public Wi-Fi hotspots. These are a few well-known “cyber hygiene” advice that apply to individuals and business employees. Notwithstanding these important practices, attackers can still find ways to break into phones, for example by exploiting unpatched security vulnerabilities or human’s moment of weakness. Therefore it is often necessary to have technology to supplement, not replace, cyber defense of our computing devices.
Identifying Smartphone Apps: Towards Malware Detection
As we will see in this lesson and other lessons in the DeapSECURE series, machine learning models can be helpful to detect cyberattacks. We will follow the idea contained in a recent research paper by Wassermann and Casas to develop simple machine learning models that can identify the applications running on an Android smartphone based on systems-related information gathered on that phone. To achieve this goal, we need to know:
-
How to handle and analyze large amounts of data (big data techniques)—this is introduced in this learning module.
-
How to perform machine learning on this data—introduced in DeapSECURE machine learning module.
-
Ultimately we will learn how to perform deep learning using neural networks to achieve the most accurate prediction. This will be the subject of the DeapSECURE neural networks module.
The techniques dentification of running applications based on their behavioral patterns can be further adapted to identification of malware. Due to the limited amount of time, we will not attempt to create a method to actually detect unusual application activities—which can lead to the detection of malware. This will be left to your own curious explorations.
The Sherlock Dataset
Motivated by the pressing concern described above, security researchers at the Ben-Gurion University of the Negev (BGU) performed a large-scale data collection experiment involving Android smartphones and real-life users. In the researcher’s words:
To assist security researchers and data scientists alike, the BGU Cyber Security Research Center has performed a multi-year data collection experiment as part of a research project with the Israeli Ministry of Space and Technology. The objective of the data collection experiment is to provide security researchers access to a labeled dataset containing a wide variety of low-privileged monitorable smartphone features that capture both regular usage and cyber-attacks. The dataset, called the “SherLock Dataset” contains billions of data records collected from 50 volunteers over a few years. The labels were created by having the volunteers run applications infected with malware—based on real malwares found in the wild. (Source: Sherlock project website, retrieved 2020-01-18)
The primary purpose of the dataset is to help security professionals and academic researchers in developing innovative methods of implicitly detecting malicious behavior in smartphones. (Source: Mirsky et al. 2016)
The data collected in this experiment can help reveal patterns and statistics related to the security of smartphones. The data can also be used to develop novel solutions to detect malware, determine user’s authenticity, and assess security status—all based on information that can be obtained in the device.
The researchers have published the dataset with its overview on their website: http://bigdata.ise.bgu.ac.il/sherlock/#/ . The following paper describes the dataset in great detail:
Yisroel Mirsky, Asaf Shabtai, Lior Rokach, Bracha Shapira, Yuval Elovici, “SherLock vs Moriarty: A Smartphone Dataset for Cybersecurity Research”, 9th ACM Workshop on Artificial Intelligence and Security (AISec) with the 23nd ACM Conference on Computer and Communications (CCS), 2016.
The Sherlock Experiment
The data collection took place from years 2015 through 2018. Fifty volunteers were given Samsung Galaxy S5 smart phones, powered by Android 5.0 operating system. These phones were not rooted, but there were two applications installed on these phones: One was the Sherlock data collection agent, and the other was the Moriarty malware app. Both applications were developed and maintained by the researchers. Other well-known applications were also present—Google Chrome, Facebook, WhatsApp, Google Maps, Waze, and many others. The participants were to use these phones regularly as if these were their own phones.

Figure: Sherlock vs. Moriarty. (Source: Time Inc.; photograph by Byron Company, New York)
Sherlock periodically collected a large number of information bits from the phones such as system and network-related statistics, as well as sensor readings (see below). Sherlock was a service process running in the background—it served no other purpose than gathering all the information bits that can be gathered from an Android phone without rooting the phone. These information bits were collected by the researchers, then compiled to become the “Sherlock dataset”.
Moriarty was an application the exhibit malware-like behavior. From the start of the experiment, Moriarty morphed itself in many different ways: as various kinds of games, web browser, utility widget, sports app, and many others. Each incarnation also came with a unique malware behavior, like: stealing contacts, photos, SMS, making fake notifications, behaving like ransomware, etc. The researchers made this application behave like a real malware, but to preserve participant’s privacy, all the stolen information bits (pictures, addresses, names, messages, etc.) were irreversibly scrambled before sending to the server.
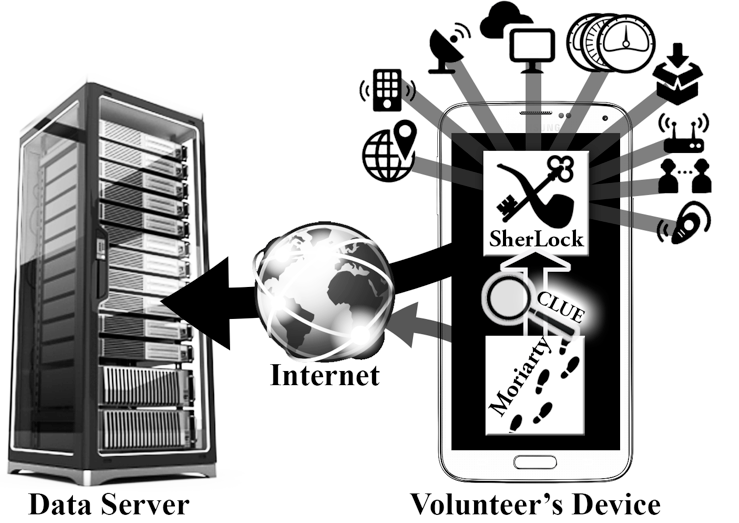
Figure: Illustration of Sherlock and Moriarty applications and the data sent by these applications to the researcher’s server. (Source: SherLock team)
In brief, in this experiment, just like in fictions written by Sir Arthur Conan Doyle, Moriarty is the app that is doing all kinds of menace on user’s phones; whereas Sherlock is doing all it can to help security researchers to detect the presence and activities of Moriarty.
What Is in Sherlock Dataset?
The Sherlock dataset contains detailed information obtained from the volunteers that used the phones loaded with Sherlock and Moriarty applications. This dataset contains both the activity stats of the computer, the running applications, and even the behavior of the human subjects (the phone users). Information gathered by Sherlock includes:
- Resource utilization per running App and overall (CPU, memory, etc.)
- Call/SMS logs
- Wi-Fi Signal strength
- Network statistics
- App install/update history
- User activity (screen on/off, user proximity)
- Hardware probes (GPS, motion/orientation sensors, etc.)
All this can be obtained without having to “root” the OS, because they are available as part of standard Linux, which is the foundation of Android OS, or they can be gathered by standard Android API. The full Sherlock dataset contains over 600 billion data points (“features”, in machine learning terminology) and 10 billion records.
The data are presented in the form of many tables, because they have diverse characteristics and are collected with different intervals. The following table summarizes the kinds of data collected, as well as a sense of the magnitude of the data. (The number of records were valid as of December 2016, but the researchers had since collected more data. The actual data collection occured till the end of 2018, if not later.) Detailed information about the data can be obtained from the Sherlock projects website.
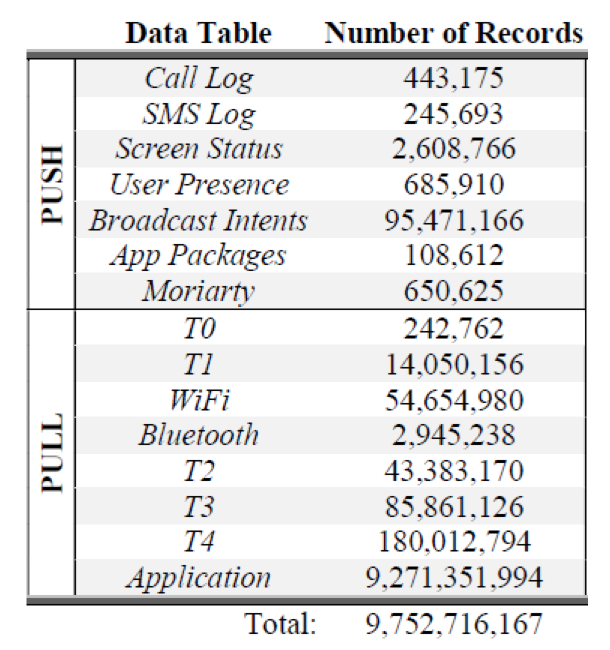
Data tables and number of records in the full SherLock dataset (as of August 2016) (Source: SherLock team)
What Are We Doing with the Sherlock Dataset?
Given the staggering details and massive volume, what can we do? An example application of the Sherlock dataset is described in a paper by Sarah Wassermann & Pedro Casas: “BIGMOMAL – Big Data Analytics for Mobile Malware Detection”, which we already referred to briefly in the introduction of this episode. In this work, the authors developed machine learning models to “identify running applications and detect malware activit[ies].” In general, one may use machine learning to identify the suspected malware in several different ways: (1) matching known malware-like patterns, or (2) detecting patterns of unusual activities that do not belong to legitimate applications.
In this training module,
we will follow the approach of Wassermann and Casas
to perform identification of running applications on a smartphone.
Our ultimate goal is to develop simple machine learning models
to predict the names of the applications running on the smartphone
based solely on resource-utilization information gathered from
Linux procfs interface.
(On Android phones, which run Linux OS under the hood,
this information is readily available for all running applications
without having to root the phone.)
Here is the goal of our activity in this “Big Data” lesson module: we will do the preparatory work by familiarizing ourselves with this dataset, and gain as many insights as we can get from the exploratory data analysis process. Achieving the ultimate goal—predicting the running applications—requires a number of additional steps that we will cover in subsequent two lessons on Machine Learning and Neural Networks.
SherLock Sample Data: Overview and Statistics
For this lesson, we will be using a sample of the Sherlock dataset, gathered from only one phone user over the period of nearly three weeks. The table below shows the various tables in the dataset, as well as the file sizes.
| File Name | File Size (Bytes) | Brief Description |
|---|---|---|
| AllBroadcasts.csv | 22,178,362 | “Broadcast” from Android OS to the apps, such as password change, network change, button presses, change in power state, etc. |
| Applications.csv | 4,571,297,916 | Records of resource usage (CPU, memory, threads, network and VM statistics) for each application, taken every 5 seconds |
| AppPackages.csv | 126,177 | Status update of apps: install, removal, upgrade, etc. |
| Bluetooth.csv | 649,965 | Information on visible (scanned) Bluetooth devices |
| Calls.csv | 159,624 | Log of phone calls: source/destination phone number, call time & duration |
| Moriarty.csv | 18,096 | “Hints” left behind by the malicious Moriarty app |
| ScreenOn.csv | 106,879 | Records of screen-on and screen-off events |
| SherLock Volunteer Survey.csv | 7,986 | Survey data collected from SherLock experiment volunteers |
| SMS.csv | 57,061 | Records of SMS messages sent and received: sender/receiver phone number, timestamp |
| T0.csv | 29,174 | Hardware and system information |
| T1.csv | 7,273,825 | Location, connected cell tower, device status |
| T2.csv | 278,306,490 | Hardware sensor data (accelerometer, gyroscope, barometer, etc.) |
| T3.csv | 64,745,896 | Audio and display device (LCD) information |
| T4.csv | 106,760,194 | Snapshots of system-wide resource usage (CPU, memory, network, battery, etc.) |
| UserPresent.csv | 23,326 | Timestaps when user begin interacting with the device |
| Wifi.csv | 10,410,473 | Information on visible (scanned) Wi-Fi access points |
We will narrowly focus on one table found in this dataset: Applications.csv.
As we will see later, this table contains the usage statistics on CPU,
memory, network, virtual machine, etc.
Certain application tend to exhibit typical characteristics
exhibited by these quantities.
We will begin to learn about these characteristics at the end of this lesson,
and continue this process using more sophisticated techniques
in the upcoming two lessons.
The table above shows that the size of Application.csv is already 4.5 GB—it is not something
we can analyze with a conventional spreadsheet software.
For this reason, we turn to pandas,
a popular Python library for data manipulation and analysis.
pandas can handle and process large amounts of data with ease.
Those with inquisitive mind are welcome to examine the sample SherLock dataset in its entirety. This lesson includes a detailed notes on SherLock dataset on a separate page, which includes information on where to find the sample dataset. Be advised that some of the data files are too large to handle with an ordinary spreadsheet program or text editor! But by completing this lesson, you will be equipped with a tool that is able to handle large datasets.
Key Points
Smartphones are a prime target of cybersecurity attacks due to its ubiquity.
Researchers use large amounts of data to develop methods to detect and thwart cyber attacks.