Communicating Data with MPI
Overview
Teaching: 30 min
Exercises: 30 minQuestions
How do we perform point-to-point communications in MPI?
How do we perform collective communications in MPI?
Objectives
Learn how to communicate between processors using MPI (specifically mpi4py).
Messages
What is a message?
A message is any information passed from one process to another.
Subsequently, a message can be any object type.
We need a structure here to handle the exchange of messages between the processes.
The structure we need here is our MPI.COMM_WORLD object comm.
comm can give us information such the rank of the process or the size of the process pool, but it can also help us send and receive messages.
The messages that are passed through comm are then transfered from node to node using the network or a bus between CPU cores (from within the same computer node).
Types of Point to Point Communication
- Unidirectional
- Bidirectional
- Multiple messages (unidirectional)
- Multiple messages asynchronously (unidirectional)
Unidirectional Messages
How do you send or receive a message with MPI4PY?
Use comm.send to send a message from one process (source) to another (dest).
It is paired with a comm.recv on the other process.

Figure 1: Unidirectional messaging.
message_to_send is sent from rank 0 to rank 1.
So, rank 0 will send the message, with the destination dest=1.
Rank 1 will recv the message from source=0.
This, and all proceeding coding files will be located in handson/mpi4py/.
Save this unidirectional messaging file as send_recv.py.
#!/usr/bin/env python3
from mpi4py import MPI
import socket
import sys
comm = MPI.COMM_WORLD #initialize the communicator
size = comm.Get_size() #number of processes
rank = comm.Get_rank() #unique ID for the calling process
host_name = socket.gethostname()
message_to_send = "SENT_FROM_RANK_" + str(rank)
if rank == 0:
comm.send(message_to_send, dest=1)
else:
received_message = comm.recv(source=0)
print("I am rank ", rank, " running on host ", host_name, \
" I received from the other rank running on host ", received_message)
I am rank 1 running on host d4-w6420b-08 I received from the other rank running on host SENT_FROM_RANK_0
Bidirectional Sending and Receiving Messages

Figure 2: Bidirectional messaging.
There is also bidirectional messsages. This requires proper ordering.
The send and recv commands are the blocking version of message passing.
This means that the program waits/blocks the process that calls the blocking communication until the data buffers involved can be safely reused by the program.
The computation time can be decreased as a result of using blocking communication since it prevents the process from doing anything else until the message is completly sent or received.
This also provides a built in synchronization of messages, but can lead to deadlock.
Deadlock happens when no process can continue. This can happen when one process is waiting on another process (or itself) to complete an action, but that process is in turn waiting for another process to complete. Thus, no change in state is possible. Deadlock can happen when there is a very large message, but this can be mitigated by using asynchronous send and receiving (in other words, using non-blocking versions of message passing).
MPI (and mpi4py) allow non-blocking and blocking communication.
Non-blocking versions of message passing is done by comm.Isend and comm.Irecv.
They allow overlap of computations and communication.
These are typically used when there is a dedicated communication controller. However, we will focus on the blocking versions of communication.
In the example below, rank 0 will (send, receive) and rank 1 will (receive, send).
This example sends one mesage from rank 0 to rank 1, and sends another message from rank 1 to rank 0.
(Here, rank 0 is just like any other rank in the MPI process world, not representing anything special such as the “master” rank.)
Notice the reversal of send and receive on the two respective ranks, because of the direction of the two messages.
Make sure to only run this with exactly two processes.
This is send_recv2.py.
#!/usr/bin/env python3
# This program demonstrates bi-directional communication using exactly two processes
from mpi4py import MPI
import socket
import sys
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# Check that we have exactly two processes otherwise terminate
if size != 2:
sys.exit("This program requires exactly two processes. Please re-run with two process.")
host_name = socket.gethostname()
message_to_send = host_name
received_message = ""
if rank == 0:
comm.send(message_to_send, dest = 1)
received_message = comm.recv(source = 1)
else:
received_message = comm.recv(source = 0)
comm.send(message_to_send, dest = 0)
print("I am rank ", rank, " running on host ", host_name, \
" I received from the other rank running on host ", received_message)
I am rank 1 running on host d4-w6420b-08 I received from the other rank running on host d4-w6420b-07
I am rank 0 running on host d4-w6420b-07 I received from the other rank running on host d4-w6420b-08
Many Sending and Receiving Messages (Tags)
Many messages can be sent using comm.send and
comm.recv, but the user needs to keep track of
the correct order of messages (as well as the
destination and source processes).
Alternatively, mpi4py allows the user the
ability to utilize tags to distinguish messages
and route them correctly.
This file is send_multi_tagged.py.
#!/usr/bin/env python3
# Send multiple messages using tags.
# This program runs with 2 processes.
from mpi4py import MPI
import socket
import sys
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# Check that we have exactly two processes otherwise terminate
if size != 2:
sys.exit("This program requires exactly two processes. Please re-run with two processes.")
host_name = socket.gethostname()
msg_send1 = "hello"
msg_send2 = 3728
msg_send3 = [1, 2, 3, 5, 8, 13, 21]
if rank == 0:
comm.send(msg_send1, dest=1, tag=1)
comm.send(msg_send2, dest=1, tag=2)
comm.send(msg_send3, dest=1, tag=3)
print("Rank", rank, ": sent 3 messages:")
print("msg_send1 =", msg_send1)
print("msg_send2 =", msg_send2)
print("msg_send3 =", msg_send3)
else:
# This works out ok for small messages, but for large messages
# this may create deadlock:
msg_recv3 = comm.recv(source=0, tag=3)
msg_recv1 = comm.recv(source=0, tag=1)
msg_recv2 = comm.recv(source=0, tag=2)
print("Rank", rank, ": received 3 messages:")
print("msg_send1 =", msg_recv1)
print("msg_recv2 =", msg_recv2)
print("msg_recv3 =", msg_recv3)
Rank 0 : sent 3 messages:
msg_send1 = hello
msg_send2 = 3728
msg_send3 = [1, 2, 3, 5, 8, 13, 21]
Rank 1 : received 3 messages:
msg_send1 = hello
msg_recv2 = 3728
msg_recv3 = [1, 2, 3, 5, 8, 13, 21]
Multiple Messages Exercise
Using tags is the best practice for sending multiple messages. However, this can also be accomplished without them, but more care must be made. Use
comm.sendandcomm.recvto send three messages, making sure to keep track of the order of the messages. Program two processes, one that will send three messages, and one that will receive the three messages: “hello,” 3728, and [1, 2, 3, 5, 8, 13, 21]. The output should look like the following. Name this filesend_multi.py.Rank 0 : sent 3 messages: msg_send1 = hello msg_send2 = 3728 msg_send3 = [1, 2, 3, 5, 8, 13, 21] Rank 1 : received 3 messages: msg_send1 = hello msg_recv2 = 3728 msg_recv3 = [1, 2, 3, 5, 8, 13, 21]Solution
#!/usr/bin/env python3 # This program sends multiple messages. # This program runs with 2 processes. from mpi4py import MPI import socket import sys comm = MPI.COMM_WORLD rank = comm.Get_rank() size = comm.Get_size() # Check that we have exactly two processes otherwise terminate if size != 2: sys.exit("This program requires exactly two processes. Please re-run with two processes.") host_name = socket.gethostname() msg_send1 = "hello" msg_send2 = 3728 msg_send3 = [1, 2, 3, 5, 8, 13, 21] if rank == 0: comm.send(msg_send1, dest=1) comm.send(msg_send2, dest=1) comm.send(msg_send3, dest=1) print("Rank", rank, ": sent 3 messages:") print("msg_send1 =", msg_send1) print("msg_send2 =", msg_send2) print("msg_send3 =", msg_send3) else: msg_recv1 = comm.recv(source=0) msg_recv2 = comm.recv(source=0) msg_recv3 = comm.recv(source=0) print("Rank", rank, ": received 3 messages:") print("msg_send1 =", msg_recv1) print("msg_recv2 =", msg_recv2) print("msg_recv3 =", msg_recv3)
Asynchronous Multiple Messages
Asynchronous messages (non-blocking) allows the
receiving process to perform (other) tasks
while waiting on the message.
Whereas, for synchronous messages, the receieving
processes must wait on the message to be received
before performing other tasks.
However, as seen in the first print statement,
asynchronous messaging requires more user
oversight.
Process 1 (the sending process) changes result, so the user needs to pay attention to whether a variable’s value is changed before, during, or after the message is received.
Create a program with two processes that send three
messages (result, result1, result3) asynchronously.
This file is called nonblocking.py.
#!/usr/bin/env python3
# Send multiple messages asynchronously between
# the sending (rank 1) and receiving (rank 0) processes.
import numpy
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# initial messages
result = numpy.array([0.])
result1 = numpy.array([2.7, 3.9])
result2 = numpy.array([0.0, 1.7, 8.0])
if rank == 1:
result = numpy.array([6.7])
print("Process", rank, " now set the variable to:", result)
req = comm.Isend(result, dest=0)
req.Wait()
print("Process", rank, " now set the variable to:", result1)
req = comm.Isend(result1, dest=0)
req.Wait()
print("Process", rank, " now set the variable to:", result2)
req = comm.Isend(result2, dest=0)
req.Wait()
if rank == 0:
print("Process", rank, "before receiving has the number", result)
req = comm.Irecv(result, source=1)
req.Wait()
print("Process", rank, "received", result)
req = comm.Irecv(result1, source=1)
req.Wait()
print("Process", rank, "received", result1)
req = comm.Irecv(result2, source=1)
req.Wait()
print("Process", rank, "received", result2)
Process 1 now set the variable to: [6.7]
Process 1 now set the variable to: [2.7 3.9]
Process 1 now set the variable to: [0. 1.7 8. ]
Process 0 before receiving has the number [0.]
Process 0 received [6.7]
Process 0 received [2.7 3.9]
Process 0 received [0. 1.7 8. ]
Collective Communication
Collective communication routines allow the user to efficiently implement data transfer from all to one, and from one to all processes at once. Instead of individually sending to all other processes or receiving from other process, collective communication routines can be used to do this more efficiently with minimal code. Collective communications include:
- Broadcast
- Scatter
- Gather
- Reduction
Broadcast
Broadcasting is sending a message from a source process (or root) to all other processes. This is often used to replicate data across all processes. This is equivalent to the following (using simple send and receive):
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
root = 0
message = ""
if rank == root:
message = "This message was broadcast by rank "+ str(root)
for i in range(1, size):
comm.send(message, dest=i)
else:
message = comm.recv(source=root)
print(message)
The following code is the proper way to broadcast.
This file is called bcast.py.
Make sure that the SLURM script uses 4 processes.
#!/usr/bin/env python3
# Broadcast message from rank 0 to the other 3 processes.
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if rank == 0:
message = "SENT_FROM_RANK_0"
else:
message = "Empty"
print("Content of message in rank ", rank, " before broadcast: ", message,
flush=True)
message = comm.bcast(message, root=0)
print("Content of message in rank ", rank, " after broadcast: ", message,
flush=True)
Content of message in rank 2 before broadcast: Empty
Content of message in rank 3 before broadcast: Empty
Content of message in rank 0 before broadcast: SENT_FROM_RANK_0
Content of message in rank 1 before broadcast: Empty
Content of message in rank 2 after broadcast: SENT_FROM_RANK_0
Content of message in rank 1 after broadcast: SENT_FROM_RANK_0
Content of message in rank 0 after broadcast: SENT_FROM_RANK_0
Content of message in rank 3 after broadcast: SENT_FROM_RANK_0
To broadcast a message, you need to provide bcast with at least two parameters: the message to transfer and the root, representing the rank broadcasting the message.
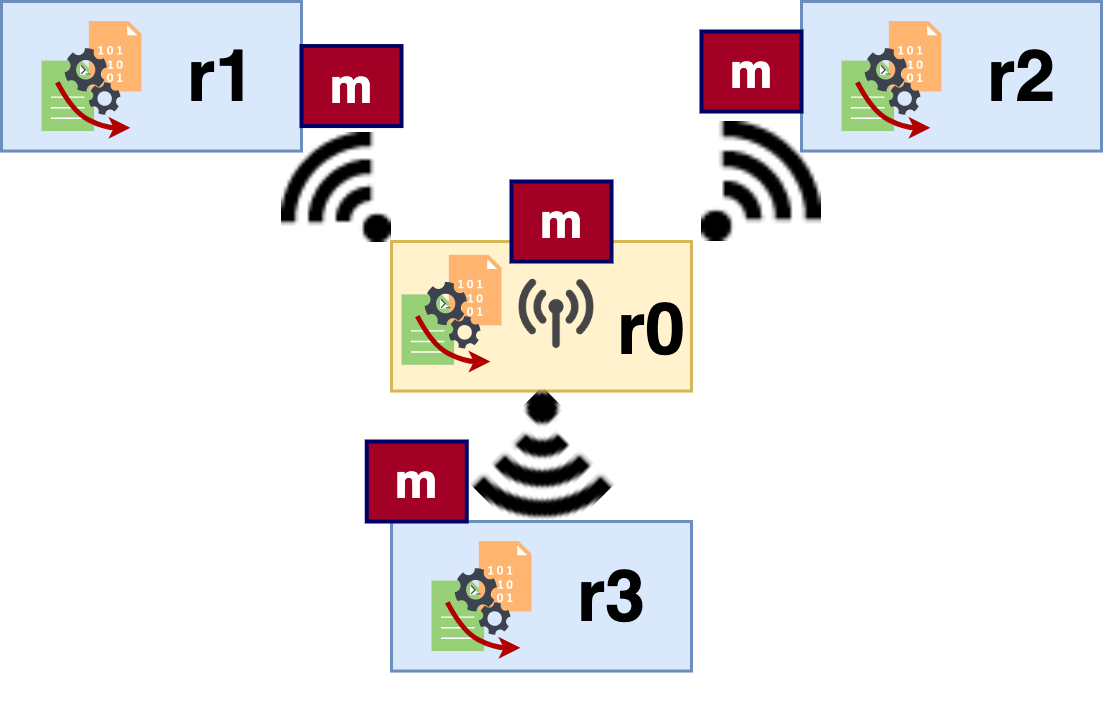
Figure 3: Broadcasting. Process r0 broadcasts message m to r1, r2, and r3.
Gather
Gathering (comm.gather) is not exactly the opposite of broadcasting.
The main difference between gathering and broadcasting is that broadcasting replicates a single message across processes.
Gathering on the other hand copies different variation of a given piece of information from all processes to one single process.
In other words, it collects distinct messages from all other ranks to one process (root).
It is useful for collecting pieces of data (or intermediate results) from processes.
The file is called gather.py.
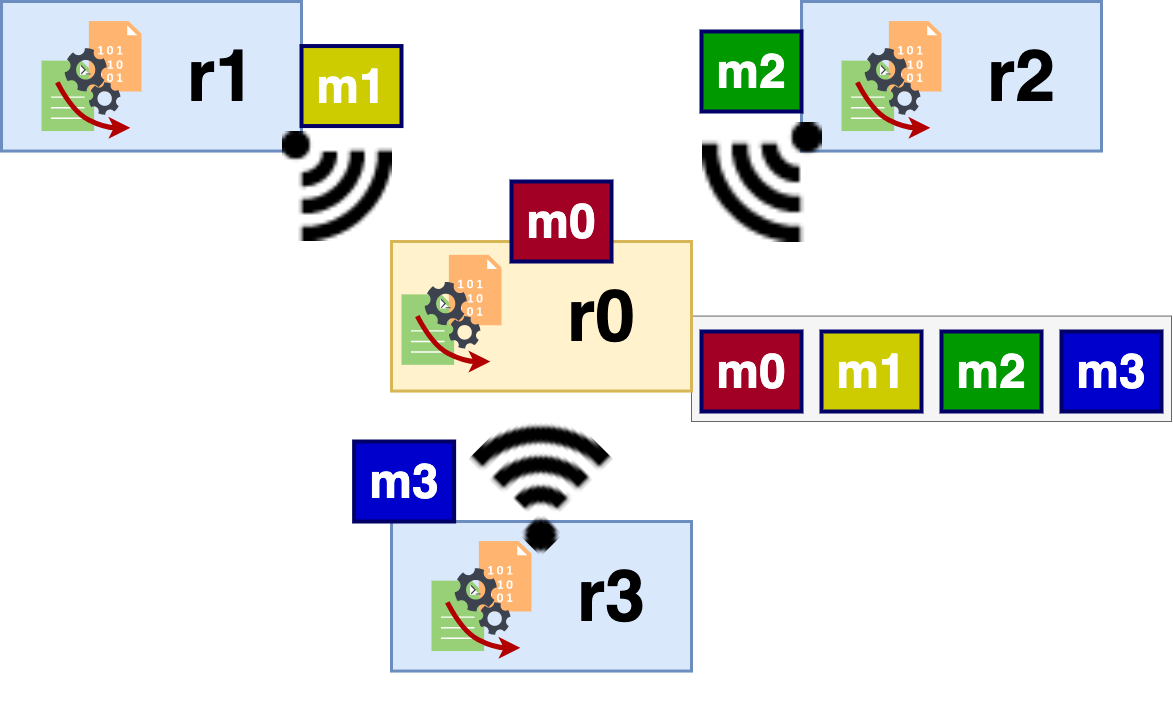
Figure 4: Gathering. Process r0 gathers the distinct messages m1 from r0, m2 from r2, and m3 from r3.
#!/usr/bin/env python3
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# the message to be gathered:
msg = rank * (rank + 1)
print("message from rank", rank, ":", msg)
#We gather all `msg` to process 0
gather_messages = comm.gather(msg, root=0)
if rank == 0:
print("Gathered messages:", gather_messages)
message from rank 2 : 6
message from rank 1 : 2
message from rank 3 : 12
message from rank 0 : 0
Gathered messages: [0, 2, 6, 12]
Similarly to bcast, gather needs at least two arguments: the data and the root, where all copies are sent.
Scatter
Scatter (comm.scatter) takes a message and divides it into chunks, then sends each chunk to a given process.
The difference between broadcast is that receiving process only get a part of the original message, this is, the chunk that has been sent to them.
For example, if the message is an array, we scatter the array. It will be ordered and divided in equal sub-arrays and then sent in order to the processes.
Note that the sending process (root) also keeps a chunk for itself.
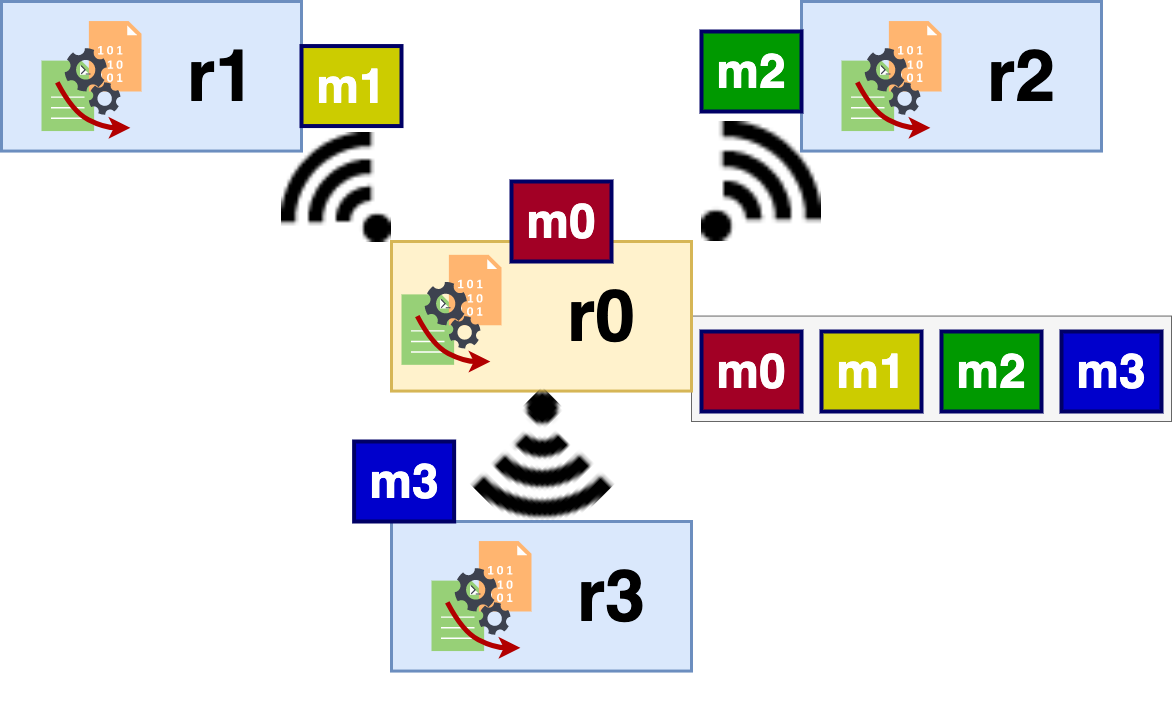
Figure 5: Scatter. The array containing the data m0, m1, m2, and m3 before the scatter is on r0. r0 scatters the array amongst itself (r0), r1, r2, and r3. m0 is scattered to r0, m1 to r1, m2 to r2, and m3 to r3.
The file is scatter.py.
#!/usr/bin/env python3
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
data = None
recv_message = None
if rank == 0:
data = ["m"+str(i) for i in range(size)]
print("Data to scatter:", data)
recv_message = comm.scatter(data, root=0)
print("After scatter, rank", rank ,"has recv_message:", recv_message)
Data to scatter: ['m0', 'm1', 'm2', 'm3']
After scatter, rank 0 has recv_message: m0
After scatter, rank 1 has recv_message: m1
After scatter, rank 2 has recv_message: m2
After scatter, rank 3 has recv_message: m3
scatter is similar to other collective routines in terms of arguments, it requires the data to scatter and the root process.
Reduce
Reduce operations allow users to apply a particular operation in parallel to multiple processes and sends the result to Rank 0. For example, when computing the sum of numbers in parallel and relaying that result to Rank 0, instead of each process sending their variables to Rank 0 and then manually implementing the sum, apply a reduction operation. Other popular reduction operations returns the maximum, minimum, product, and bitwise logical operations (such as AND and OR).
This is a useful and efficient way to compute these values in parallel. Internally, each process is given a chunk of the data to work with and then calculates its intermediary value before broadcasting its result and Rank 0 receiving all other processes results to calculate the overall result.
Some examples are included in reduce.py:
#!/usr/bin/env python3
from mpi4py import MPI
import numpy as np
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
# Create some np arrays on each process:
# For this demo, the arrays have only one
# entry that is assigned to be the rank + 1 of the processor
value = np.array(rank+1,'d')
print(' Rank: ',rank, ' value = ', value)
# initialize the np arrays that will store the results:
value_sum = np.array(0.0,'d')
value_max = np.array(0.0,'d')
value_min = np.array(0.0,'d')
value_prod = np.array(0.0,'d')
# perform the reductions:
comm.Reduce(value, value_sum, op=MPI.SUM, root=0)
comm.Reduce(value, value_max, op=MPI.MAX, root=0)
comm.Reduce(value, value_min, op=MPI.MIN, root=0)
comm.Reduce(value, value_prod, op=MPI.PROD, root=0)
if rank == 0:
print(' Rank 0: value_sum = ',value_sum)
print(' Rank 0: value_max = ',value_max)
print(' Rank 0: value_min = ',value_min)
print(' Rank 0: value_prod = ',value_prod)
Rank: 2 value = 3.0
Rank: 1 value = 2.0
Rank: 3 value = 4.0
Rank: 0 value = 1.0
Rank 0: value_sum = 10.0
Rank 0: value_max = 4.0
Rank 0: value_min = 1.0
Rank 0: value_prod = 24.0
reduce requires at least four parameters: the data on which the computation is done (array here), the variable to store the result of the operation (value_min, value_max, value_sum), the aggregate function to use on the data (for example, op=MPI.MIN, MPI.MAX, MPI.SUM), and the root.
root will be in charge of computing the final result from intermediary results coming from other processes.
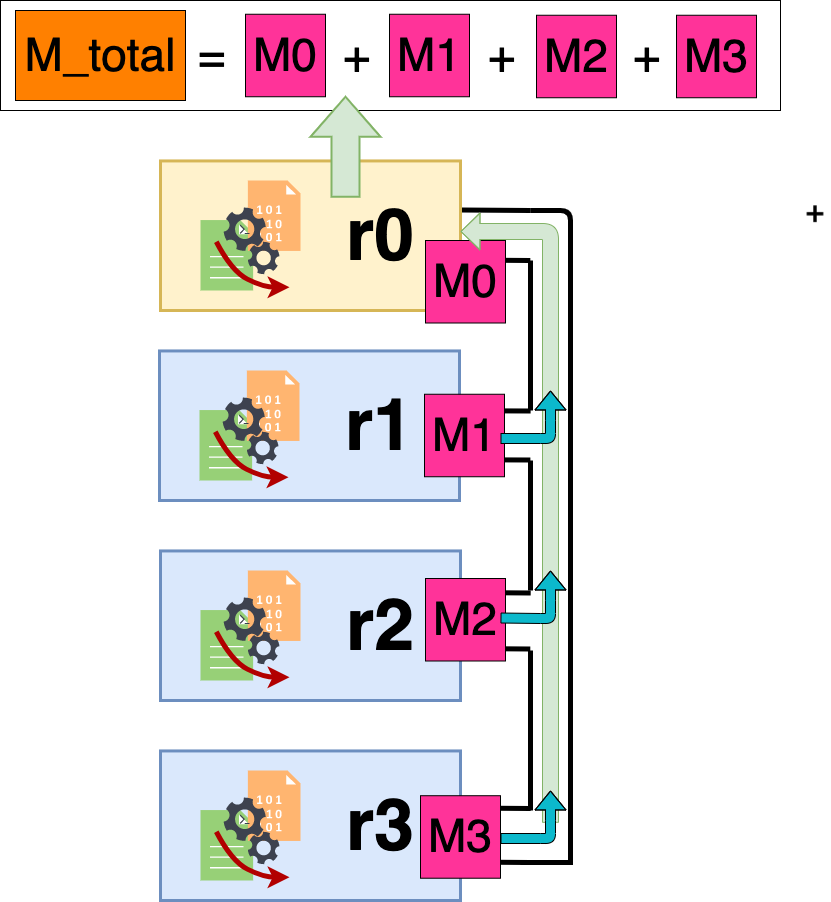
Figure 6: Using Reduce to get the sum over the processes. Each process has their own locally saved variable data (M0, M1, M2, and M3). The values are sent to r0 where it applies a summing function. The total is saved in the variable M_total.
Here is an example using reduce to apply MPI.SUM.
#!/usr/bin/env python3
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
my_number = rank * rank
print("Content of my_number in rank", rank, " = ", my_number,
flush=True)
SUM_NUMBER = comm.reduce(my_number, op=MPI.SUM, root=0)
if rank == 0:
print("SUM_NUMBER after summation:", SUM_NUMBER,
flush=True)
Content of my_number in rank 0 = 0
Content of my_number in rank 1 = 1
Content of my_number in rank 2 = 4
Content of my_number in rank 4 = 16
Content of my_number in rank 5 = 25
Content of my_number in rank 3 = 9
SUM_NUMBER after summation: 55
It is important to note that all processors participate when using collective communications.
Barrier: Synchronizing Workers
comm.barrier prevents workers from proceeding until all processors reach a particular point.
It allows the parallel program to reach a consistent global state.
In other words, all of the data values are up-to-date and all processors have reached the same simultaneous time marker.
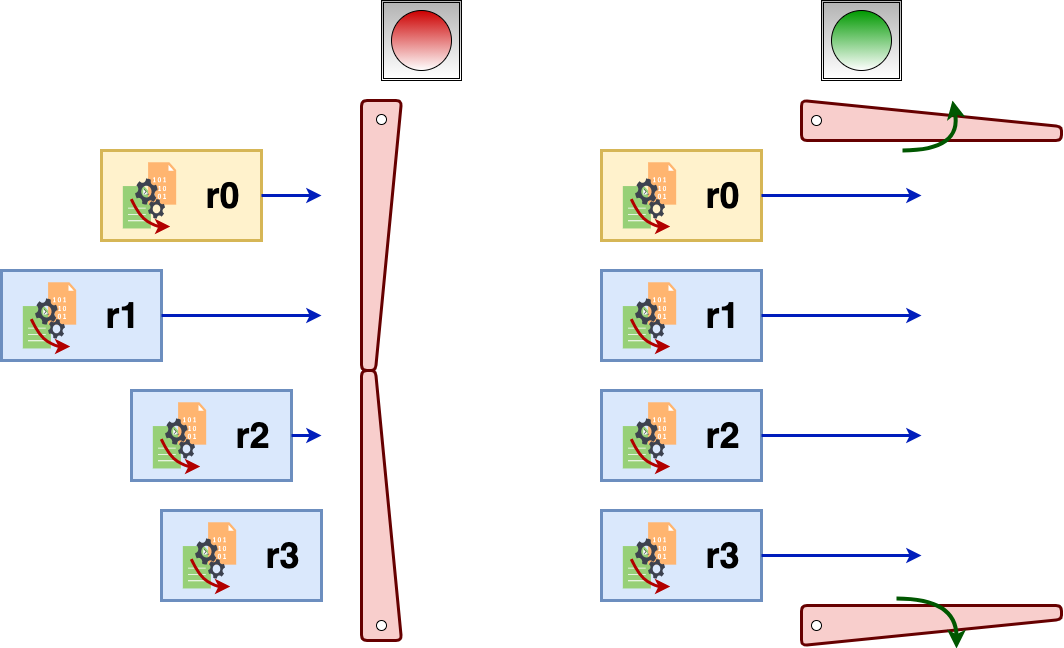
Figure 7: Shows how barrier synchronizes the workers. The left side shows the before barrier states of the processors r0, r1, r2, and r3. The right side shows after the barrier, where all processors start in synch.
Run barrier.py.
#!/usr/bin/env python3
from mpi4py import MPI
import time
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
if size != 4:
sys.exit("This program requires exactly four processes. Please re-run with four processors.")
# file path
file_name = "1000_num.txt"
data = None
t0 = time.time()
time0 = comm.bcast(t0, root=0)
if rank == 0:
file_name = "1000_num.txt"
# Read the numbers from file into an array
with open(file_name) as fd:
lines = fd.readlines()
data = [int(x.strip()) for x in lines]
fd.close()
elif rank == 1:
# pretend this rank does some type of work for 5 seconds
time.sleep(5)
print("Rank 1 finished work, it took", '%.2f' %(time.time()-time0), "seconds. \n")
elif rank == 2:
# pretend this rank does some type of work for 7 seconds
time.sleep(7)
print("Rank 2 finished work, it took", '%.2f' %(time.time()-time0), "seconds. \n")
else:
# pretend this rank does some type of work for 15 seconds
time.sleep(15)
print("Rank 3 finished work, it took", '%.2f' %(time.time()-time0), "seconds. \n")
comm.barrier()
print("Rank", rank, "after barrier, start work after", '%.2f' %(time.time()-time0), "seconds.")
Rank 1 finished work, it took 5.01 seconds.
Rank 1 after barrier, start work after 15.03 seconds.
Rank 2 finished work, it took 7.01 seconds.
Rank 2 after barrier, start work after 15.03 seconds.
Rank 3 finished work, it took 15.03 seconds.
Rank 3 after barrier, start work after 15.03 seconds.
Rank 0 after barrier, start work after 15.03 seconds.
Hands-on : Sum of numbers across MPI4PY processes
Problem
We are given a large file containing a number of integers, one per line. We are tasked with doing a simple computation on these numbers, calculate the mean of the squared values from the numbers in the given file. We have the formula:
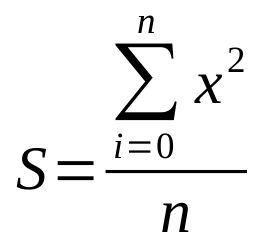
Figure 8: Mathematical equation for the this hands-on problem.
The solution should be a parallel python program that reads in the given input file containing the numbers to use for the computation.
Solution
See parallel_square_mean.py and serial_square_mean.py.
We start by writing a serial version of our program:
#!/usr/bin/env python3
import time
# file path
file_name = "1000_num.txt"
# Read the numbers from file into array
data = None
with open(file_name) as fd:
lines = fd.readlines()
data = [int(x.strip()) for x in lines]
fd.close()
t0 =time.time()
# Number of values
n = len(data)
# Square values
squares = [x**2 for x in data]
# Sum of all squared numbers
sum_squares = 0
for i in range(n):
sum_squares = sum_squares + squares[i]
# Calculate mean of squares
squares_mean = sum_squares / n
t1 = time.time()
# Print result
print("The calculated squares mean is : ", squares_mean, "\nComputation time : ", t1-t0)
Now that we have a working serial program, we need to add parallel constructs to make it work in parallel.
We first need to divide the data fairly so that each process will have the same amount of work to do.
This is simple, since we have n numbers, we need to divide n by the total number of process, let say p.
Now, what happens if we do not have an exact division of data among the processors? If n/p does not equal an integer, there is a remainder and the workload cannot be (exactly) evenly split.
In this instance, we evenly split the data (in “chunks”) among the processors, then add the remainder, starting from process 0, adding one at the time.
# Number of values
n = len(data)
# Chunk size
chunk = int(n / size)
if n % size > 0:
if rank < n % size:
chunk = chunk + 1
Now that we know what chunk size each process will work on, we need to know where does each process chunk starts. This is the offset, which is just the amount of work all processes before the current process has to work on.
# Number of values
n = len(data)
# Chunk size
chunk = int(n / size)
if n % size > 0:
if rank < n % size:
chunk = chunk + 1
# Offset
offset = rank * chunk
if rank > n % size:
offset = offset + n % size
Now each process knows what amount of work it has to accomplish and where its part of the work starts. Now, we can re-write our program to incorporate the parallel programing concepts.
One way to solve this problem is to do the following.
The program will use rank 0 to read in the text file that contains the numbers.
This data is then broadcast to the other processes.
The chunk size and offset amounts are calculated (based on the number of processors).
Each processor calculates the intermediate result for their chunk of data (sum the squared values).
gather collects the intermediate results from each process on rank 0.
Process 0 then uses the gathered results to calculate the mean of the squares.
#!/usr/bin/env python3
from mpi4py import MPI
import time
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
# file path
file_name = "1000_num.txt"
data = None
if rank == 0:
file_name = "1000_num.txt"
# Read the numbers from file into an array
with open(file_name) as fd:
lines = fd.readlines()
data = [int(x.strip()) for x in lines]
fd.close()
# Broadcast data to all processes
data = comm.bcast(data, root=0)
t0 = time.time()
# Number of values
n = len(data)
# Chunk size
chunk = int(n / size)
if n % size > 0:
if rank < n % size:
chunk = chunk + 1
# Offset
offset = rank * chunk
if rank > n % size:
offset = offset + n % size
print("Rank ",rank," offset ",offset)
# Square values
my_squares = [x**2 for x in data[offset:offset + chunk]]
# Sum of all squared numbers
my_sum_squares = 0
for i in range(chunk):
my_sum_squares += my_squares[i]
# Now we gather all my_sum_squares in process 0 to calculate the overall mean
sums = comm.gather(my_sum_squares, root=0)
# Process 0 does the rest of the work
if rank == 0:
# Overall sum
sum_squares = 0
for i in range(size):
sum_squares += sums[i]
# Calculate mean of squares
squares_mean = sum_squares / n
t1 = time.time()
# Print result
print("The calculated squares mean is : ", squares_mean, "\nComputation time : ", t1-t0)
Where to go from here?
For more information on MPI4PY, you can consult the project’s page at: Read the docs MPI4PY
Key Points
A message can be any object type.
There are different types of communication types.