Introduction to MPI: Distributed Memory Programming in Python using mpi4py
Overview
Teaching: 20 min
Exercises: 0 minQuestions
What are the key elements of MPI?
What is MPI4PY?
Objectives
Understanding distributed-memory parallel programming basics
Getting familiar with MPI4PY Python module
Introduction to MPI
Message Passing Interface (MPI) is a standard specification for a distributed-memory, message-passing, parallel programming model. As we will learn in this lesson, message passing indicates the primary way for individual processes to communicate and exchange data with one another. MPI is implemented as a software library instead of an extension built into existing programming languages, or a completely new programming language. As a result, it is rather straightforward to add parallel programming capabilities to new languages which were not a part of the official MPI standard specification.
What Is mpi4py
The mpi4py library provides a convenient programming interface
to use MPI from Python programming language.
mpi4py relies on a C implementation of MPI library
to provide a distributed-memory, message-passing capabilities
for Python programmers.
Components of Parallel Programming Covered by MPI
The key approach of a parallel program is to divide up the work into parts that can be executed concurrently/simultaneously, so that the entire computation will take a shorter amount of time. Parallel programming, therefore, involves:
Problem decomposition – dividing up work into a set of tasks that can execute independently, and assigning these tasks to the workers, often the responsibility of the programmer to implement;
Concurrency – making workers carry out their respective tasks at the same time;
Communication – coordinating and exchanging data with among the workers as necessary.
Different workers will be assigned to work on different parts of the same data (known as data parallelism) or to work on (completely) different tasks that can be processed concurrently (task parallelism).
Basic Capabilities of MPI
There are two main types of communication that the mpi4py provides.
The first is point-to-point communication and the second is collective communication.
Point-to-Point Communication
Point-to-point communication sends data from one worker to another (who receives the data). This is done through send and receive commands.

Figure 1: One worker - r0 sends a message to another worker r1. Worker r1 receives the message from r0. Then, r1 sends a message to r0; r0 also receives the message from r1.
Collective Communication
Collective communication transfers data from one worker to many others (or many-to-one, or many-to-many). These communications include broadcasting (one-to-many), scatter (one-to-many), gather (many-to-one), and reduction (many-to-one).
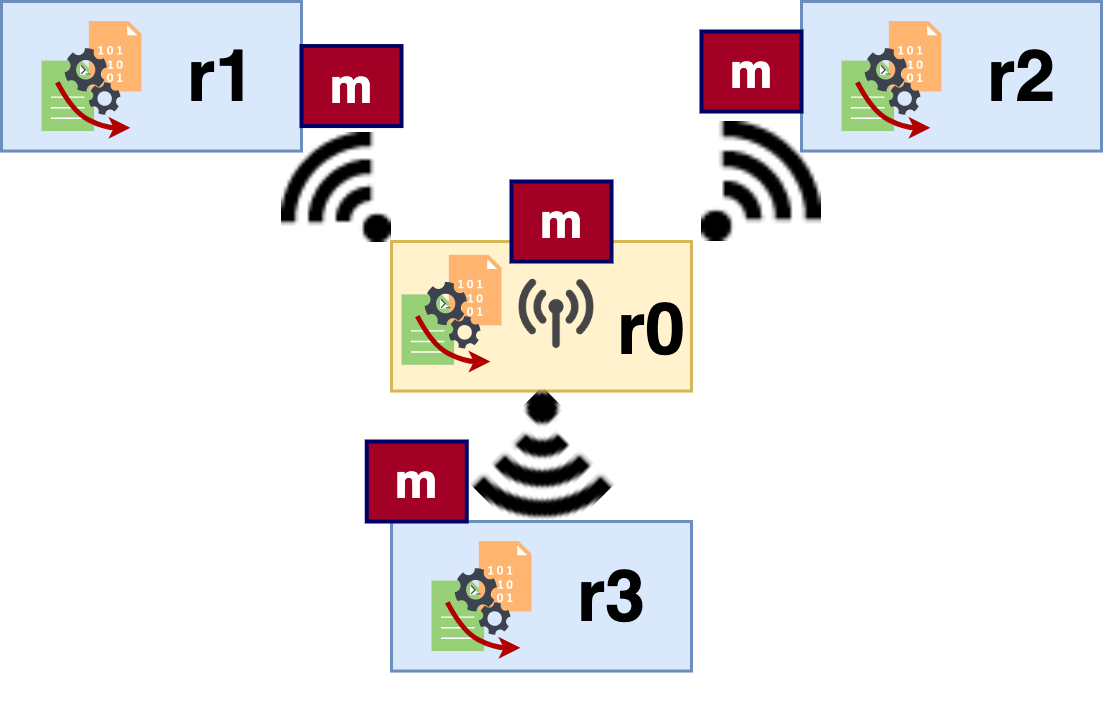
Figure 2: One of the collective communication types, broadcast. Worker r0 broadcasts the message m to the other three workers - r1, r2, and r3.
Process Synchronization
Process synchronization allows parallel programs to reach a consistent global state. Barrier is an example of process synchronization.
How to Run a MPI4PY Program/First MPI4PY Program
Go to
mpi4pyHands-on DirectoryPlease go to the
~/CItraining/module-par/mpi4pydirectory where you will be working throughout this episode. This directory contains the sample programs and scripts to demonstrate the features and capabilities of MPI in Python.
For this lesson, and the next subsequent lesson, all of the necessary python files will be in the /handson/mpi4py/ directory/folder or /handson/mpi4py/solution/. The scripts used to run the python files are in /handson/mpi4py/slurm-scripts/.
There are two common ways of running MPI programs. One is through the job scheduler (SLURM). The less traditional method is to launch the MPI program directly from the Jupyter session. Under most circumstances, you need to submit the MPI-based programs to the HPC job scheduler since they tend to consume a lot of resources (memory and CPU).
Running an MPI4PY program is simple. You need to make sure the right libraries are loaded (see Setup page). Note, it is important to consult your cluster documentation and adjust the commands accordingly!
In the SLURM script (.slurm file), you will need to indicate the amount of computing
resources required. These computing resources
can then be futher allocated for tasks in the slurm script.
In the script (used to run the python file), there will be 4 workers (i.e. processes, or ntasks), all located on a singular node (by default). With the mpiexec command, the user can specify the actual number of processes to use during the execution of the code, which in this example is also 4.
Best practice is to only request the minimum number of computing resources necessary to run the given scripts. See slurm documentation for more information.
Write your first mpi4py program.
In this tutorial, we will name the file hello_world.py in the learner’s directory.
#!/usr/bin/env python3
print("Hello world!")
We will run this program using the following SLURM batch script
(save this as hello_world.slurm).

(The job script above is fairly general and
can be adapted to other MPI program invocations.
Simply replace the program name
and adjust the job name [--job-name argument]
and the output filename [--output argument].)
To run the job, open the terminal and submit this script:
$ sbatch hello_world.slurm
As with other jobs, sbatch will print a short message with the job number,
such as: Submitted batch job 3366124.
Now that our job was submitted, we can check its status using squeue
(remember to replace USER_ID by your own HPC username):
$ squeue -u USER_ID
Since this program is very simple, it is possible this job will not be displayed,
since the job may have already been executed and completed.
When our job is completed, we can find the output from
the output file we specified in the batch script
(the #SBATCH --output=hello_world.out).
We can view this file (hello_world.out) to check the result
of this job:
Hello world!
Hello world!
Hello world!
Hello world!
Why Four Lines in Output?
The Python program has only one
Hello world!output. Why did it produce four identical messages when it is launched using MPI in the example above?Solution
The
mpiexecspecifies-n 4, which means that it requests to launch four workers to run this program in parallel. Each worker will run the same program (hello_world.py) and execute all the instructions contained therein. Because of this, four print statements were executed (one per each worker).
Understanding why there are four lines of Hello world!
is a very important step toward understanding how a parallel program would work.
The example above demonstrates that:
MPI launches a parallel program consisting of one or more workers (processes) which run the same executable code.
If there are four processes running the same executable code, then how would MPI enable the processes to split up one problem into multiple pieces and work on them together? This is where communication and process coordination would be necessary. MPI provides all these capabilities.
Note, workers, processors, and ranks are often used interchangeably in documentation. Likewise, task, job, programs, and process are often interchangeable.
Communicator, Process Rank, and Number of Ranks
In MPI, a parallel program consists of a set of processes (independently-running programs) that use the MPI library functions to communicate with one another. In order to successfully write an MPI program, we need to be aware of three basic elements: communicator, rank, and number of ranks. A communicator is a collection or pool of processes in a MPI program.
In the following program, we create a communicator comm from the MPI default communicator, MPI.COMM_WORLD.
MPI.COMM_WORLD is the collection of all processes (ranks) in a given execution of the program.
Other communicators can be created from a subset of ranks from MPI.COMM_WORLD.
The communicator is used to manage operations between process and extract information on the MPI execution such as process rank and number of processes in the communicator.
In our program, size represents the number of processes in MPI.COMM_WORLD. In other words, the total number of processes for a given execution.
rank is the unique ID for the calling process.
When an MPI program is executed, processes are spawned at initialization time, before the main parts of the program are executed.
Each process has its own PID, a process ID which is given by the operating system and has nothing to do with rank here.
rank is an internal (to the program execution) identification of processes.
Each process has its own unique rank, always a number between 0 and n-1 where n is the total number of processes in the execution.
Within a communicator, each process will be able to inquire the number of processes in that group, as well as its own rank.
Now, look at the code of rank_size.py.
#!/usr/bin/env python3
from mpi4py import MPI
comm = MPI.COMM_WORLD # initialize the communicator
size = comm.Get_size() # get number of processes
rank = comm.Get_rank() # get unique ID for *this* process
print("Hello from process ", rank, " part of a pool of ", size, " processes.")
Let us use the rank_size.slurm script to run rank_size.py,
which introduces some tweaks compared to the previous job script:
#!/bin/bash
#SBATCH --job-name=rank_size
#SBATCH --ntasks=7
#SBATCH --output=%x.out
#SBATCH --open-mode=truncate
module load container_env
module load DeapSECURE/2023
module load python3
mpiexec -n 4 rank_size.py
The output file argument %x.out has a special substring %x,
which will be replaced by the actual name of the job given to SLURM
when the job is submitted.
Go ahead and submit the job to SLURM and observe the output.
Here is an example output:
Hello from process 1 part of a pool of 4 processes.
Hello from process 3 part of a pool of 4 processes.
Hello from process 0 part of a pool of 4 processes.
Hello from process 2 part of a pool of 4 processes.
Compare the example output above with your own output, and answer the following questions:
- Are your output exactly identical to that shown above?
- Why are the rank numbers printed in the output lines not ordered sequentially (0, 1, 2, 3)?
The sequence of the numbers printed in the output seems arbitrary and will change from one run to another. (Try submitting the job several times and observe the order of the numbers printed.) The lack of order in the printed messages indicates another important feature of a parallel program: The processes are not launched synchronously, and each of them runs independently of each other. For example, in printing messages out to the terminal, the processes do not wait for each other. Which message arrives first at the terminal is indeterminate. This lack of synchronization is an important feature of concurrency in parallel programming.
In general, concurrency in parallel program leads to asynchronous execution among the different processes.
Use the Right Number of Resources!
The job script above has one peculiarity: It requests 7 cores to run the Python script, but when MPI program is invoked, the
mpiexec -n 4makes MPI launch only 4 processes. Thus, there are 3 additional cores available to the program that will not be used. This is allowable by SLURM, as long as the number of processes does not exceed the number of the cores reserved. Under normal circumstance, this would be considered an inefficient use of resources, since we reserve more than what we need. It is a good practice to only allocate the number of cores that you need to use. Go ahead and edit therank_size.slurmfile to reflect the correct amount.As an experiment, adjust the number 4 in the
mpiexecinvocation up and down. Will the program still run? What are the contents of the output? Will there be a case where the program would refuse to run?Solution
The program will run with
-nbetween 1 and 7 (inclusive). It will print that many number of lines, showing the different ranks participating in the run. However, the program will refuse to run if we set-nargument to be 8 or greater. It may fail with an error like this (see the output file):srun: error: Unable to create step for job 3366221: More processors requested than permittedIn this case, SLURM refuses to launch the program because it was asking for more cores than what was reserved through SLURM (the
--ntasks = 7line).
How to Make Processes Do Different Things?
As shown earlier, we launch n copies of processes using MPI, each executing the same program (i.e. the same set of instructions).
How can then we make these programs do different things?
The secret lies in the MPI-defined rank of a process: we use the if (rank == SOMETHING) ... else construct throughout an MPI program to decide what needs to be done by each process.
In the next lesson, we will see how this construct is being used in two settings: (1) to set up the so-called “master process” to handle things on behalf of all the processes; (2) to send and receive messages.
Rank 0
In an MPI program, process rank 0 has a special role to coordinate the work for and results from the other processes. This is called the “master rank” or “master process.” The master process typically also reads the input file(s), saves the results to the output file(s), and prints messages while the program is running. Depending on the nature of the computation, rank 0 may participate in the computation as one of the workers, or simply coordinating the other processes (which can be the case if this role already makes the processor very busy).
The if rank == 0: ... statement encloses statements that will be executed by only process rank 0.
Key Points
Processes can exange information using MPI4PY constructs.
Messages can be any object types.
Commuincations can be peer to peer (
comm.sendandcomm.recv) or collective (comm.gather,comm.scatter…).An MPI4PY
COMM_WORLDobject is necessary to manage operations between processes.Use of
if (rank == SOMETHING) ... elseconstruct to make processes execute different tasks.Rank 0’s special role.