Running Spam Analyzer on a High-Performance Computer System
Overview
Teaching: 15 min
Exercises: 15 minQuestions
How do we run computational jobs on a modern HPC system?
Objectives
Explain the standard way of submitting and running jobs on an HPC system.
Use SLURM parameters to specify resource requirements for a job.
Why Job Scheduler?
A job scheduler in computing can be likened to a restaurant’s host managing customers. In this analogy, jobs are the customers, each with varying durations, sizes, and resource requirements. The goal of the job scheduler, like the host, is to ensure that all jobs are executed with the appropriate resources, providing a fair share among users while maximizing resource utilization. This ensures efficient and effective handling of multiple jobs, much like a host optimizes seating arrangements and service quality in a busy restaurant.
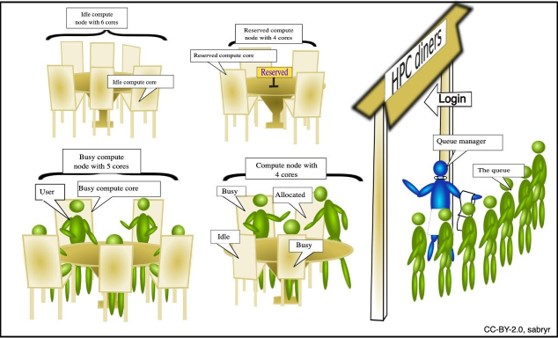
SLURM: A Job Scheduler on HPC
SLURM is an open-source job scheduler designed for HPC. It’s particularly popular in academic and research institutions, where users require efficient resource management for running compute-intensive tasks.
SLURM operates on a simple principle: users submit job scripts containing the necessary instructions for their computations, and SLURM takes care of scheduling, resource allocation, and job execution. Here’s a step-by-step breakdown:
- Creating a Job Script: Users craft a job script, which is essentially
a UNIX shell script with additional directives at the top, including
a
#SBATCHline specifying parameters for SLURM. - Submitting the Job Script: Once the job script is ready, users submit it to SLURM using the sbatch command.
- Queuing the Job: SLURM places the job in a queue, awaiting available resources.
- Resource Allocation: SLURM continuously monitors the cluster’s resources and identifies suitable nodes based on the job’s requirements (e.g., CPU, memory, GPU).
- Launching the Job: Once appropriate resources are found, SLURM reserves them and launches the job on the selected nodes.
- Execution: The job executes according to the instructions in the script, performing the desired computations.
- Input and Output Handling: Input data required for the computation is typically read from files specified in the job script, while output is directed to files as well. This ensures a structured approach to data handling and management.
Running Spam Analyzer on HPC
To process data on the HPC using SLURM,
we first need to create a job script tailored for the task.
Let’s name it month03.slurm to process the data on March 1998.
In this script, we specify essential parameters for SLURM using directives.
For instance:
#!/bin/bash
#SBATCH --job-name month03
module load DeapSECURE
./spam_ip.sh 1998/03
This script, month03.slurm, sets the job name as “month03”
and loads necessary modules like DeapSECURE.
It then executes a script named spam_ip.sh with the argument 1998/03,
indicating the March 1998 dataset to process.
Once the month03.slurm script is prepared,
it can be submitted to SLURM for execution using the sbatch command:
sbatch month03.slurm
Upon submission, SLURM assigns a process ID to the job, confirming its submission:
Submitted job 70592
Now, to track the progress of our job, we can use the squeue command with our user ID:
squeue -u USER_ID
This command provides a status update on all our submitted jobs, including their current state within the queue.
Additionally, SLURM automatically directs
the output of our job to a designated file,
typically named slurm-JOB_ID.out. For instance,
in this case, the output would be directed to slurm-70592.out.
Lastly, if there’s a need to cancel the task for any reason,
we can use the scancel command followed by the job’s process ID:
scancel 70594
This command effectively terminates the specified job, freeing up resources for other tasks in the queue. Overall, this workflow provides a structured and efficient approach to managing computations on HPC clusters using SLURM.
Exercise
create a second script to process April 1998
For evaluating performance and measuring runtime,
we can incorporate timing into our job script.
Let’s name this script runtime_month03.slurm. Here’s how it looks:
#!/bin/bash
#SBATCH --job-name month03
module load DeapSECURE
d1=$(date +%s) # measure begin time (in sec)
./spam_ip.sh 1998/03
d2=$(date +%s) # measure end time (in sec)
echo 'Total time to run is' $(($d2 - $d1)) 'seconds'
When comparing the runtime of processing different datasets, such as the March 1998 and April 1998 collections. Please think these questions:
- Does the runtime differ when processing the March 1998 and April 1998 email collections, and if so, what could be the underlying reasons for this difference?
- Could the variance in runtime be attributed to the number of spam emails present in each directory?
Common Job Parameters
SLURM provides a wide range of job parameters that can be specified
in the job script using the #SBATCH directive.
These parameters allow users to customize the behavior of their jobs
and specify resource requirements.
Here are some commonly used job parameters:
-
--job-name: Specifies a name for the job. This parameter is important for identifying and tracking the job in the scheduler. It can be set to a descriptive name that reflects the purpose or nature of the job. For example,--job-name=myjobor--job-name=spam_analysis. -
--outputor-o: Specifies the file where the standard output of the job will be written. This parameter allows you to redirect the output of your job to a specific file. For example,--output=output.txtor-o output.log. By default, the output is written to a file namedslurm-JOB_ID.out. -
--error: Specifies the file where the standard error of the job will be written. Similar to the--outputparameter, this allows you to redirect the error output of your job to a specific file. For example,--error=error.txtor--error=error.log. By default, the error output is written to the same file as the standard output. -
--timeor-t: Specifies the maximum time limit for the job in the formatdays-hours:minutes:seconds. T his parameter sets a limit on the total runtime of the job. If the job exceeds this time limit, it will be terminated. For example,--time=1-12:00:00sets a time limit of 1 day and 12 hours. -
--nodesor-N: Specifies the number of nodes required for the job. This parameter allows you to request a specific number of compute nodes for your job. For example,--nodes=4or-N 4requests 4 compute nodes for your job. -
--ntasksor-n: Specifies the number of tasks to be launched on the allocated nodes. This parameter allows you to specify the number of parallel tasks that will be executed as part of your job. For example,--ntasks=8specifies that your job will launch 8 parallel tasks. -
--partition: Specifies the partition or queue where the job should be submitted. This parameter allows you to specify the partition or queue where your job should be scheduled. For example,--partition=computeor--partition=debug. -
--mail-user: Specifies the email address where job-related notifications should be sent. This parameter allows you to receive email notifications about the status of your job. For example,--mail-user=user@example.comspecifies that notifications should be sent touser@example.com. -
--mail-type: Specifies the type of job-related notifications to be sent via email. This parameter allows you to control the types of notifications you receive. For example,--mail-type=BEGIN,END,FAILspecifies that notifications should be sent at the beginning, end, and in case of failure of your job. -
--cpus-per-task: Specifies the number of CPUs (or cores) required per task. This parameter allows you to request a specific number of CPUs for each task in your job. For example,--cpus-per-task=4specifies that each task in your job requires 4 CPUs.
These are just a few examples of the job parameters that can be used with SLURM. For a complete list of available parameters and their descriptions, refer to the SLURM documentation.
Monitoring and Managing SLURM Jobs
Once you have submitted your job to SLURM, you may want to monitor its progress and manage it as needed. SLURM provides several commands for this purpose:
-
salloc: This command allows you to allocate resources and obtain an interactive shell on a compute node. It is useful for testing and debugging your job before submitting it to the queue. -
srun: This command is used to launch parallel tasks on the allocated compute nodes. It allows you to specify the number of tasks, the task distribution, and other parameters. -
hostname: This command can be used within ansruncommand to display the hostname of the compute node on which a task is running. It is useful for verifying the distribution of tasks across nodes. -
scancel: If you need to cancel a job for any reason, you can use thescancelcommand followed by the job ID. This will terminate the job and free up resources for other tasks in the queue. -
squeue: This command allows you to view the status of all jobs in the queue. By runningsqueue, you can see information such as the job ID, job name, user, state, and time remaining for each job.
These commands provide you with the ability to monitor the progress of your jobs, check their resource usage, and cancel them if necessary. By effectively monitoring and managing your SLURM jobs, you can ensure efficient utilization of resources and timely completion of your computations.
Processing Multiple Months’ Data
To streamline the process of processing the entire year’s
data of 1998, we can create a custom script to automate
the execution of spam_ip.sh for each month.
nano run_spam_ip.sh
Copy this to the file.
#!/bin/bash
./spam_ip.sh 1998/03
./spam_ip.sh 1998/04
./spam_ip.sh 1998/05
./spam_ip.sh 1998/06
./spam_ip.sh 1998/07
./spam_ip.sh 1998/08
./spam_ip.sh 1998/09
./spam_ip.sh 1998/10
./spam_ip.sh 1998/11
./spam_ip.sh 1998/12
Instead of running individual commands for each month, which can be
tedious and time-consuming, we can consolidate all commands into a
single script. This script will iterate over each month of the year,
invoking spam_ip.sh with the appropriate argument for the corresponding dataset.
Here’s how we can achieve this:
- Copy the Template Script
Start by copying the templates/year1998.template script to create a new script
for each month. The template script should include the general structure and
commands needed to run the spam_ip.sh script.
cp templates/year1998.template ./spam_ip_1998.slurm
- Adjust the Script for SLURM Compatibility
Modify the copied script to include SLURM directives.
These directives will specify job parameters such as job name,
resource requirements, and output settings.
nano spam_ip_1998.slurm
#!/bin/bash
#SBATCH --job-name year1998
#SBATCH --time 2:00:00
module load DeapSECURE
YEAR=1998
# Hint: We have months: March through December (03 .. 12)
d1=$(date +%s)
for MONTH in ##EDIT...
do
##EDIT...
done
d2=$(date +%s)
echo 'Total time to run is' $(($d2 - $d1)) 'seconds'
Once the scripts are prepared, we can execute them individually or submit them to SLURM for batch processing. SLURM will handle the scheduling and execution of each script, ensuring efficient utilization of resources and timely processing of the entire year’s data.
To estimate the time needed to compute the entire 1998 dataset, we can initially calculate a rough estimate using simple multiplication. We can multiply the time taken to process a single month (for example, March 1998) by the total number of months in the year (10 months).
After making this initial estimate, we can proceed to run the spam_ip_1998.slurm script and measure the actual runtime.
By comparing the estimated time with the actual runtime, we can determine if the estimate is accurate or if adjustments are needed.
Upon completion of the computation, we can analyze the actual runtime and compare it with our initial estimate. If the actual runtime significantly deviates from the estimated time, it indicates that the estimate was off. This could be due to various factors such as variations in dataset sizes, computational complexity, or system resource availability.
For quick testing or one-time runs, we can execute the script immediately on a compute node without a full batch script submission.
srun -t 4:00:00 -n 1 ./spam_ip.sh 1998/03
HPC clusters have time limits and jobs that are running can take a long time.
Imagine that when you are running a long job with srun above,
unfortunately there is a power outage or network outage that interrupts the remote terminal connection.
What will happen to your job?
The answer is that the job will be terminated
because srun is interactive and its processes are typically linked to the terminal session.
To solve this problem, we will study the batch job scheduler in the next episode.
Exercise
Try the same processing for 1999, 2000
Exercise
- To get the # of spam email for a month you can do this:
ls MONTH | wc -l- Can you get the # of spam emails for all months in a given year
- What do you see in years 1999, 2000, 2001
Solution
for month in * do echo $month: ls $month | wc -l done
Key Points
A job script is used to launch a computation job on an HPC system.